Services for EPFL researchers and PhD students









Publishing support
The Library offers its expertise and its support during all publication processes, from the writing to the diffusion of the research output.

Publishing Support Fast Guides
Open Access: the basics | Make your research open | Creative Commons Licenses | Publishing agreement | Exception for educational purposes | How to reuse a work properly

“Publish your thesis while respecting copyright” guide
This detailed guide provides information on how to reuse other content while respecting the rules of copyright.

OACT
Compare Open Access publication conditions of research institutions, funders and scientific journals.
Research data management (RDM)
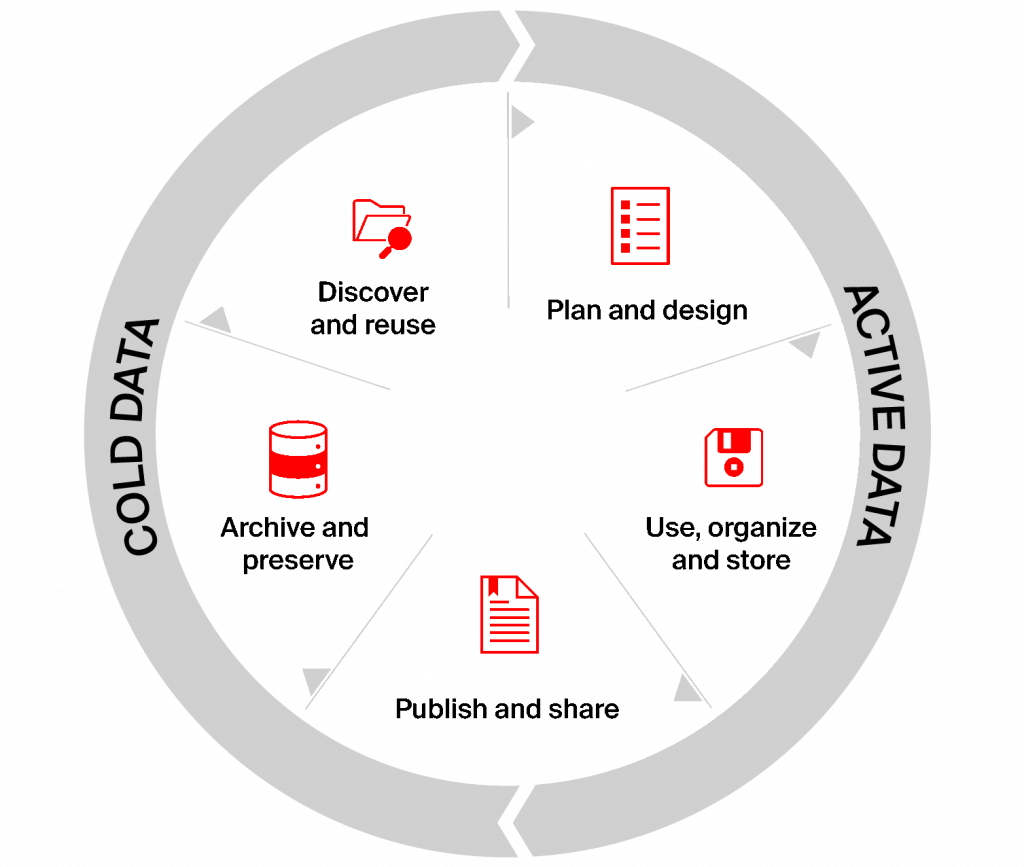
Research Data Management (RDM) refers to the way research data and code are managed during the entire research project. A dedicated Research Data Team at the EPFL Library supports EPFL researchers in the management of their data and code, providing tools and guidance at any step of the data life cycle, in accordance with the principles of FAIR data and Open Science.
Data planning and guidelines

Data Management Plan (DMP): templates, reviews, checklists, funders guidelines…
Active data management

Metadata, formatting, version control, workflows and protocols, Electronic Laboratory Notebooks (ELN), Laboratory Information Management System (LIMS), storage and backup…
Data publication

Data publication, data dissemination platforms, data repositories, data journals, EPFL Zenodo Community…
ACOUA:
Long-term preservation

Archiving data at the EPFL through ACOUA, the ACademic OUtput Archive
Data policies

FAIR principles, Open Data (ORD), data and code licenses, personal and sensitive data, data protection, anonymization…
Data services, expertise, tools and training

Personalized RDM support, DMP reviews and preparations, ACOUA support, EPFL Zenodo Community management, Training and courses, Book a data librarian, EPFL Data Champions community coordination, How to get in touch…




Open Science initiative
EPFL Library participates in the EPFL global initiative to support Open Science.